تعرف الخط
تعرف خط
handwriting recogntion -
تعرف الخط
محمد الشايطة
كان تعرف الخط Handwriting Recognition (HWR) موضع اهتمام الباحثين لعدة عقود. وبعد أن طورت أنظمة التعرف recognizers الأولى من أجل تعرف المحارف المنفصلة أو الأرقام ركزت أنظمة التعرف الحديثة على تعرف كلمات كاملة أو جمل. وقد اقترحت في الوقت الحاضر بعض الحلول التي تحقق أداء جيداً في تعرف الخط؛ مثل أنظمة التعرف المقدمة من مايكروسوفت وكائنات الرؤية Vision Objects. ومع ذلك لا يمكن الافتراض أن مهمة تعرف الخط قد تم حلها حلاً كاملاً، فما يزال هناك مجال لتحسين أداء التعرف، والتعامل مع نصوص مختلفة وبيئات خاصة. ويصرف الكثير من الجهد البحثي حالياً في اتجاه تحسين التعرف في حالات الاستخدام هذه.
إن النهج الأكثر حداثة في تعرف الخط هو فهم معنى المحتوى المكتوب بدلاً من مجرد تعرف النص المكتوب بخط اليد. وليس مهماً بالنسبة إلى العديد من التطبيقات الحصول على تشكيلات الكود القياسي الأمريكي لتبادل المعلومات (الأسكي) American Standard Code for transcription Information Interchange (ASCII) فقط، ولكن المهم أيضاً تعرف المحتوى والمفاهيم الموجودة في الوثيقة، حيث يمكن أن يستخدم هذا المحتوى من أجل تصنيف الوثيقة، أو حتى ربطها بغيرها من الوثائق، وبالمفاهيم المعرفة في فضاء المعرفة لشخص أو لشركة ما.
إن أنظمة تعرف الخط تنهج الخطوات الأساسية نفسها التي تنفذ في تعرف المحارف والأرقام وغيرها، حيث تتمحور معظم الأبحاث حالياً حول التعمق في إحدى المراحل وتطويرها. ويوضح الشكل (1) الخطوات الرئيسية التي تؤدي إلى تعرف الخط. وتتكون من خمس مراحل، هي: المعالجة الأولية preprocessing، التسوية (الاستنظام) normalization، استخراج المزايا feature extraction، التصنيف classification، أخيراً مرحلة ما بعد المعالجة postprocessing .
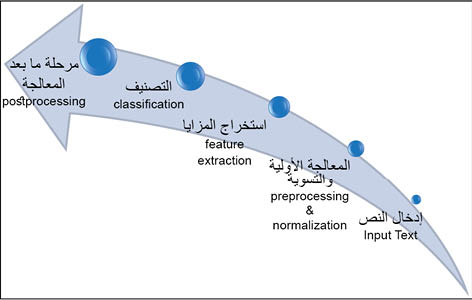 |
| الشكل (1) النظام العام لتعرف الخط. |
1- مرحلة المعالجة الأولية:
مرحلة المعالجة الأولية هي الخطوة الأولى المهمة في أي نظام تعرف الخط، حيث يتم التخلص فيها من الضجيج المصاحب للعينة المدخلة من النص. وغالباً ما تشمل هذه الخطوة عدة خطوات لازمة لتشكيل الصورة المدخلة وتحويلها إلى شكل مناسب لعملية التجزئة segmentation، مثل عملية استخلاص الخط line extraction، وأحياناً فصل الكلمة، وتجزئة الحرف character segmentation اعتماداً على مهمة التعرف. وتعد عملية تجزئة الحرف على أية حال مشكلة صعبة للغاية؛ لأنه ليس من الممكن تجزئة الكلمة إلى أحرف قبل تعرف الكلمة نفسها، ومن جهة أخرى لا يمكن أن يتم تعرف الكلمة تعرفاً صحيحاً قبل أن تتم تجزئتها إلى أحرف. ويعرف هذا الوضع بأنه مفارقة ساير Sayre’s paradox. تتم في هذه العملية تجزئة الصورة المدخلة إلى أحرف فردية، وبعد ذلك تغيير حجم كل حرف إلى m x n بيكسل باتجاه شبكة التدريب. ويظهر الشكل (2) مختلف المهام التي تجرى على الصورة المدخلة في مرحلة المعالجة الأولية.
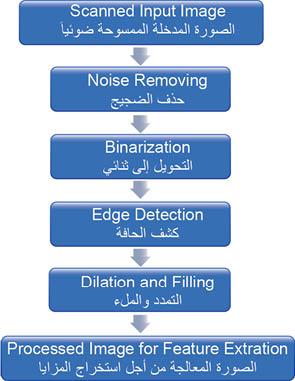 |
| الشكل ( 2) المهام التي تجرى على الصورة المدخلة في مرحلة المعالجة الأولية. |
وقد اقتُرحت مجموعة كبيرة ومتنوعة من أساليب التجزئة في العقود الماضية، ويعد بعض التصنيف ضرورياً لتعرف الحرف تعرفاً صحيحاً هنا. ومع ذلك لا يبدو أن هناك تصنيفاً منفصلاً ممكناً، لأنه قد يشترك نهجان من التجزئة مختلفان جداً في الخصائص التي تتحدى التصنيف المفرد. أما في الوقت الحاضر فتُستخدم التصنيفات الآتية:
- التجزئة المعتمدة على العتبة threshold based segmentation:
تستخدم تقنيات مخطط العتبة والتقطيع في تجزئة الصورة، ويمكن تطبيقها مباشرة على أي صورة، ولكنها يمكن أن تُستخدم أيضاً جنباً إلى جنب مع تقنيات قبل المعالجة وبعدها.
- التجزئة المعتمدة على الحافة edge based segmentation:
يفترض بهذه التقنية أن تكون الحواف المكتشفة في صورة ممثلة لحدود الكائن، وتستخدم أيضاً لتحديد هذه الكائنات.
- التجزئة المعتمدة على المنطقة: region based segmentation
بما أن التقنية المعتمدة على الحافة قد تحاول العثور على حدود الكائن أولاً، ومن ثم تحديد الكائن نفسه عن طريق ملء تلك الحدود، فإن التقنية المعتمدة على المنطقة تأخذ النهج المعاكس، فتبدأ مثلاً من منتصف الكائن ثم تتوسع إلى الخارج حتى حدود الكائن.
تقنيات التجميع clustering techniques:
في هذه التقنية يتم تجميع الأنماط المتشابهة في بعض الخصائص، وهذا الهدف يشبه إلى حد بعيد مايتم تنفيذه عند تجزئة الصورة، بل يمكن أن تطبق بعض تقنيات التجميع فعلاً لتقطيع الصورة.
المطابقة matching:
عندما يُعرف كيف يبدو كائن ما يمكن تعرفه من صورته تقريباً، ثم مطابقتها مع أي صورة لتحديد ذلك الكائن. ويسمى هذا النهج بالتجزئة المطابقة.
2- مرحلة التسوية normalization:
تقلل التسوية من تأثير أساليب الكتابة المختلفة عن طريق تسوية بيانات المدخلات المكتوبة بخط اليد. ويمكن أن تعدّ هذه المرحلة أيضاً تابعة للمرحلة السابقة. يجري في مرحلة التسوية تعديل انحراف المحارف وميلانها وطولها وعرضها.
3- مرحلة استخراج السمات feature extraction:
في هذه المرحلة يتم استخراج مجموعة من عناصر السمات من عينة الإدخال. وتعد هذه الخطوة ضرورية، لأن المصنِّف classifier يحتاج عادة إلى قيم عددية تكون مدخَلات بدلاً من استخدام بيانات تسلسل النقاط الخام. وربما يعد اختيار الطريقة المناسبة لاستخراج السمات العامل الأكثر أهمية في تحقيق أدا تعرف عالٍ. وقد جرى تطوير عدة طرائق لاستخراج السمات في أنظمة تعرف الحرف.
إن أكثر أساليب استخراج السمات استخداماً هي مطابقة القالب template matching، والقوالب القابلة للتشوه deformable templates، وتحوّلات الصورة الموحدة unitary image transforms، والرسم البياني graph description، ومخططات الإسقاط projection histograms، وملامح المحيط contour profiles، والتقسيم المناطقي zoning، وثوابت العزوم الهندسية geometric moment invariants، وعزوم زيرنيكه Zernike (نسبة للفيزيائي فريتس زيرنيكه Frits Zernike 1988-1966)، وتقريب الشريحة المنحني spline curve approximation، وواصفات فورييه Fourier descriptors، وسمة التدرج gradient feature، وسمات غابور features Gabor.
من السمات الخاصة التي استخدمها الباحثون على نطاق واسـع الاختـلافات بين الإحـداثيات المتجاورة (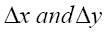 )، وميلان خط المماس عند كل نقطة (يمكن أن تعطى كزاوية)، وأحياناً قيمة التقوس عند كل نقطة. ومن هذه الخصائص أيضاً:
)، وميلان خط المماس عند كل نقطة (يمكن أن تعطى كزاوية)، وأحياناً قيمة التقوس عند كل نقطة. ومن هذه الخصائص أيضاً:
-
نسبة العرض إلى الارتفاع aspect ratio.
-
النسبة المئوية من عدد البيكسل فوق نصف النقطة الأفقية horizontal half point.
-
النسبة المئوية من عدد البيكسل إلى اليمين من نصف النقطة العمودية vertical half point.
-
عدد جرات القلم number of strokes.
-
متوسط المسافة من مركز الصورة.
-
انعكاسه بالنسبة للمحور Y.
-
انعكاسه بالنسبة للمحور X.
4- مرحلة التصنيف:
التصنيف هو عملية يتم من خلالها تغذية المصنِّفات بعناصر السمات المستخرجة مثل نماذج ماركوف المخفية Hidden Markov Models (HMMs)، والشبكات العصبونية (Neural Networks (NNs للحصول على مرشِّحي التعرف. ويتم في كثير من الأحيان تقديم بدائل متعددة من قبل المعرِّف recognizer جنباً إلى جنب مع وجود نسبة احتمال التعرف. تستخدم الشبكة العصبونية الصنعية خلفية لأداء مهام التصنيف والتعرف. وفي نظام التعرف غير الآني off-line recognition system ظهرت الشبكات العصبونية بوصفها أدوات سريعة وموثوقاً بها للتصنيف نحو تحقيق دقة تعرف عالية.
وقد طُبقت تقنيات التصنيف على تعرف الحروف المكتوبة بخط اليد منذ عام 1990. وتشمل هذه الطرائق الأساليب الإحصائية المبنية على أساس قاعدة القرار لبايز Bayes decision rule، والشبكات العصبونية الصنعية Artificial Neural Networks (ANNs)، بما فيها طرائق النواة المتضمنة آلات متجِهات الدعم Support Vector Machines (SVM)، والمصنفات المتعددة المجمعة.
يتعامل نموذج مجال تصنيف الأنماط pattern classification field المطور منذ نحو نهاية القرن العشرين مع أكثر المشكلات تحديداً من حيث تعيين إشارات الإدخال إلى صنفين أو أكثر. وتعد الأنظمة الخبيرة المجتمعة هي المصنِّفات، ونتيجة الجمع هي أيضاً مصنِّف. يمكن أن تكون مخرجات المصنِّفات متجِهات من الأرقام، حيث إن بعد المتجِهات مساوٍ لعدد الأصناف. ونتيجة لذلك يمكن تعريف مشكلة التركيب، كمشكلة العثور على تابع تركيب يقبل نقاط متجِهات مساوٍ لعدد أبعاد N-dimensional من عدد M من المصنِّفات، ويعطي في النتيجة عدداً من نقاط التصنيف النهائية مساوياً لـ N (الشكل 3)، حيث يكون التابع أمثلياً لدرجة مقبولة، مع تقليل تكلفة الخطأ في التصنيف.
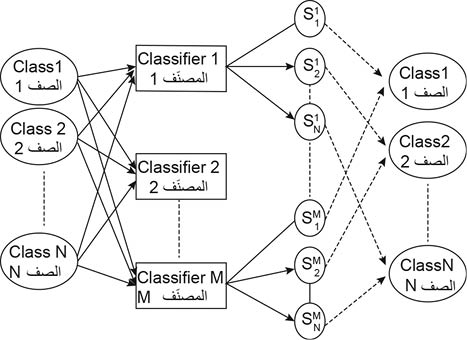
الشكل (3) تركيب المصنِّفات وتجميعها يأخذ مجموعة من نقاط للصنف i من قبل المصنف j ، ويعطي نقاط تركيب لكل صنف i. 5- مرحلة ما بعد المعالجة postprocessing:
تضم هذه المرحلة عدة خطوات يجري تنفيذها على ناتج المعرف. ويمكن في كثير من الأحيان استخدام معاجم الكلمات أو حتى قواعد النحو لتحسين نتيجة التعرف.
بعد أن يُعرف النهج العام في تعرف الخط ومراحله العامة يبين الشكل (4) المعالجة العامة لتعرف الخط بالأسلوب المباشر والآني on- line.
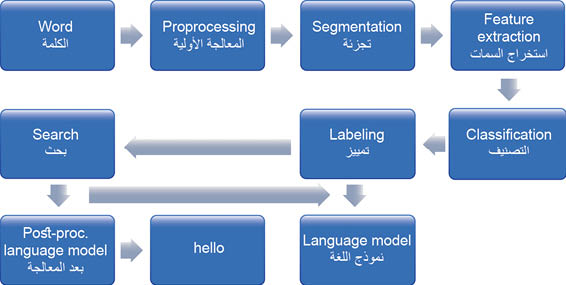
الشكل (4) المعالجة العامة لتعرف الخط بالأسلوب المباشر والآني on- line. تتبع الأبحاث الحالية في تعرف الخط نهجين أساسيين مختلفين. يتم في النهج الأول تعرف الأحرف المنفصلة أو الأرقام isolated characters or digits. ولذلك عند التعامل مع أحرف غير منفصلة -على سبيل المثال- في الكلمات أو النص يجب أن تكون البيانات مجزأة مسبّقاً. يستخدم النهج الثاني تعرف الكلمات المستمر continuous word recognition، وهذا يعني أنه يمكن افتراض بداية كل حرف أو نهايته في كل موضع. وهذه الطريقة مستخدمة على نطاق واسع من قبل المعرِّفات المبنية على نموذج HMM المذكور سابقاً.
1- تعرف الحروف المنفصلة أو الأرقام: isolated characters or digits recognition
ما يجب القيام به عند تعرف حرف منفصل أو رقم هو تصنيف مدخل واحد من البيانات كحرف أو رقم. يتم التعرف باستخدام مصنِّف أو عدة مصنِّفات. وأبسط طريقة لتعرف الخط في صورة تحتوي على رمز واحد مطابقته مع الجار الأقرب Nearest Neighbor (NN) أو طريقة k-NN. والخوارزميات الأكثر تطوراً وتحقق نتائج أفضل من الخوارزمية البسيطة NN هي الشبكات العصبونية الصنعية (ANNs)، وآلات متجهات الدعم (SVMs). فمثلاً: في معرف الشبكة العصبونية الصنعية يتعلم المعرِّف الشكل من مجموعة صور تدريبية أولية، ومن ثم تتولى الشبكة المدرَّبة تعرف الحرف. تتعلم كل شبكة عصبونية الخصائص التي تميز صور التدريب منفردة، ومن ثم تبحث عن خصائص وسمات مماثلة في الصورة الهدف المراد تعرف حروف فيها. تمتاز الشبكات العصبونية بكونها سريعة البناء والتهيئة، ومع ذلك يمكن أن تكون غير دقيقة إذا تعلمت الخصائص غير المهمة في البيانات الهدف.
2 - تعرف الكلمات المستمر: continuous word recognition
خلافاً للتعرّف المنفصل لا يتطلب التعرّف المستمر صورة مدخلات مجزأة. وأكثر أنظمة التعرّف الشائعة هي المبنية على نماذج ماركوف المخفية HMM التي تتيح فرضيات حدود الحرف والكلمة في كل موضع من الصورة المدخلة. ويتم اختيار الفرضية الأكثر احتمالاً في مرحلة الأمثلة optimization step المترافقة مع الحروف المتعرفة. إن مهمة التعرّف المستمر هي تعرّف عدد غير معروف من الكلمات ضمن عينة إدخال واحدة. ويفيد الذكر أن نظم التعرّف الحالية قادرة على تحقيق معدلات تعرّف بين 50-80% اعتماداً على إعدادات التعرف. والإعدادات الممكنة هي على سبيل المثال تعرّف سطر أو جملة. وتتعامل الإعدادات السابقة مع تعرّف سطر واحد في نص واحد في صفحة مكتوبة بخط اليد، وبالتالي تكون الصعوبة في تعرّف الكلمات المتصلة بواصلة (خط قصير) hyphenated words في نهاية السطر أو بدايته مما يزيد عدد الكلمات الممكنة. وعلاوة على ذلك يكون عدد الجمل في سطر واحد غير منتظم. ولأن الجمل ربما لا تبدأ مع أول كلمة وتنتهي مع الكلمة الأخيرة في السطر، لا يمكن لمعظم مجاميع النص أن تستخدم لإيجاد نماذج لغة Language Models (LMs) من دون مزيد من المعالجة.
أما إعدادات تعرّف الجملة فهي حالة خاصة من تعرّف السطر، حيث يحتوي السطر الواحد على جملة واحدة بالضبط. يعد تعرّف الجملة أسهل من تعرّف السطر إذ لا يتوقع وجود واصلات بين الكلمات، وتظهر علامات الترقيم دائماً في الموضع الأخير ضمن السطر. والإعداد الثالث الممكن هو تعرّف كلمة واحدة، ويمكن أيضاً أن ينظر إليه على أنه حالة خاصة من تعرّف سطر، إذ يحتوي كل سطر على كلمة واحدة. تحقق معدلات التعرّف بهذا الإعداد نسبة تفوق 90%.
سمحت التطورات في مجال الإلكترونيات أن تناسب القدرة الحاسوبية اللازمة لتعرّف الخط شكلاً أصغر من الحواسيب اللوحية، وغالباً ما يستخدم تعرّف الخط طريقة إدخال لأجهزة المساعد الرقمي الشخصي باليد Personal Digital Assistant (PDA). وكان أول PDA يوفر إدخال الكتابة يدوياً هو جهاز من شركة آبل اسمه آبل نيوتن Apple Newton، يسمح بالاستفادة من واجهة مستخدم مبسطة. فالحاسوب اللوحي هو حاسوب محمول خاص يزود بلوح تحويل رقمي وقلم، ويسمح للمستخدم بكتابة نص بخط اليد على الشاشة، ويتعرف نظام التشغيل الخط ويحوله إلى نص مطبوع. يشمل البرنامج ويندوز فيستا Windows Vista، وويندوز 7 Windows 7 السمات الشخصية التي تتعلم من خلالها أنماط كتابة المستخدم أو مفردات اللغة الإنكليزية واليابانية والصينية التقليدية والصينية والكورية. ومن أهم التطبيقات في هذا المجال:
-
التعرّف الآني عبر الإنترنت online recognition.
-
التعرف بشكل مستقل offline recognition.
-
التحقق من التوقيع signature verification.
-
تفسير العنوان البريدي postal-address interpretation.
-
معالجة الشيك المصرفي bank-check processing.
-
تعرّف الكاتب writer recognition.
على الرغم من أن دقة التعرف الآلي على الخط قد شهدت تطوراً واسعاً في السنوات الأخيرة نتيجة اعتمادها المتزايد على التعلم الآلي، ماتزال هناك إمكانات كثيرة لتحسين هذه الدقة وزيادة الاعتماد على هذا النوع من الأنظمة. وتجرى حالياً الكثير من البحوث حول تطبيقات التعلم العميق deep learning في التعرف الآلي على الكتابة اليدوية.
يمكن في المستقبل البحث في زيادة متانة النظام للتعامل مع الحالات التي تحتوي على جرّات القلم المتأخرة قبل الانتهاء من جزء الكلمة (التوقع المسبّق للكلمة قبل استكمالها). كما أن مجالات البحث في تعرّف الخط تضيف منطقة أخرى مهمة للبحث، وهي تعرّف الأشكال المرسومة باليد وإعادة رسمها حاسوبياً بالشكل الصحيح. والنهج الأكثر حداثة في تعرّف الخط والذي يجب أن يهتم به الباحثون هو فهم معنى المحتوى المكتوب بدلاً من مجرد تعرّف النص المكتوب بخط اليد.
|
مراجع للاستزادة: - M. Cheriet et.al, Arabic and Chinese Handwriting Recognition, Springer-Verlag Berlin Heidelberg, 2022. - T. Plötz, G. A. Fink, Markov Models for Handwriting Recognition, Springer, 2012. - S. Tulyakov et al., Review of Classifier Combination Methods, Machine Learning in Document Analysis and Recognition Book, Studies in Computational Intelligence, 2008. |
- التصنيف : كهرباء وحاسوب - النوع : كهرباء وحاسوب - المجلد : المجلد التاسع، طبعة 2025، دمشق مشاركة :

اخترنا لكم
المجلدات الصادرة عن موسوعة العلوم والتقانات










